多重解像度セマンティックモデルを用いた画像認識
現在のインターネット上での画像検索は、予め手動で付与されたメタデータ(画像に付与された情報)を基に検索を行っている。
しかしこの方法では時間、人件費共に膨大なコストが発生してしまう。
そこで画像から色や形状などの特徴量を自動抽出し、コンピュータに学習させ自動でアノテーション(メタデータの付与)する。
本研究の目標はこの方法を用いることでコストの問題を解決すると共に精度の高い画像検索システムを作成することである。
様々な画像の中でもシーン画像は空や建物など複数の要素から構成されており、画像の局所的な情報が重要となる。
従来は分割した局所画像の情報を基に画像をアノテーションするセマンティックモデルという手法が考案されていた。
本研究では、図1に示すように、セマンティックモデルによるアノテーションの結果から信頼性を計算し、
その結果から最適な分割数を選択する手法を提案した。
この手法を用いることで今まで以上に幅広いシーン画像に対応することができ、
図2に示すように従来よりも精度の高いアノテーションを行えるようになった。
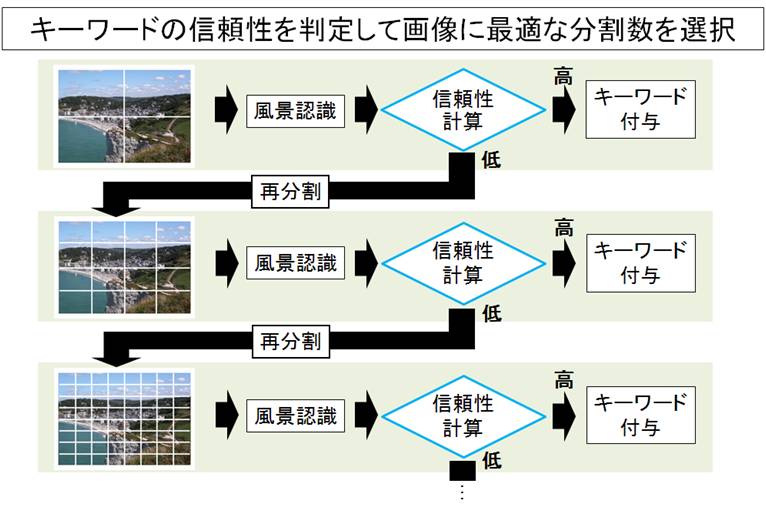
図 1 提案手法の流れ
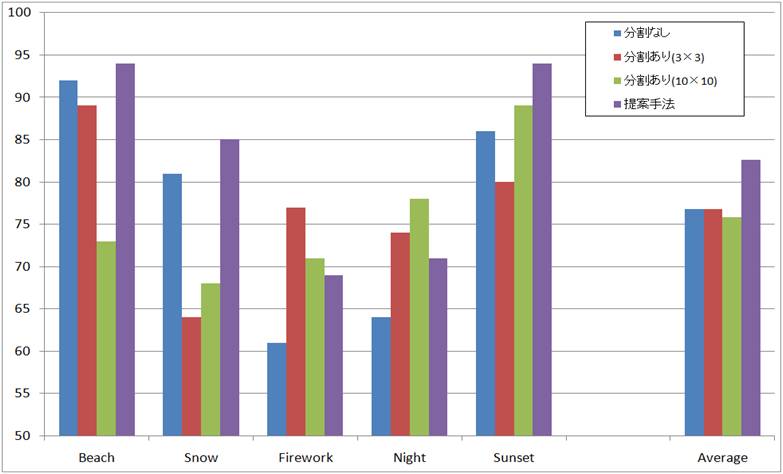
図 2 従来法と提案法の結果比較
関連研究発表:
1. 田中,岡本,韓,阮,陳:”多重解像度セマンティックモデルを用いた画像のシーン認識,” 信学技報,Vol.10, No.27, pp.169-174 (2010-5).
2. Yoshiyuki Tanaka, Atsushi Okamoto, Xian-Hua Han, Xiang Ruan, Yen-Wei Chen, “Scene Image Recognition with Multi Level Resolution Semantic Modeling”, Proc. Of SEDM, Chengdu, China, pp.644-648(2010-6).