A Static2Dynamic GAN Model for Generation of Dynamic Facial Expression Images
Facial expression generation, especially dynamic facial expression generation from a static natural (expressionless) face image, plays an important role in the fields of entertainment,
game, and social communication. Several approaches based on machine learning including deep learning techniques have been developed or proposed for facial expression generation. However, most of them are focused on static facial expression generation. In this research, we propose a static-to-dynamic model (static2dynamic) based on a 3D conditional generative adversarial network (Fig.1). Herein, the dynamic facial expression image is treated as a 3D image. The effectiveness of the proposed method is demonstrated by generating dynamic smile and angry facial expression images (Fig.2).
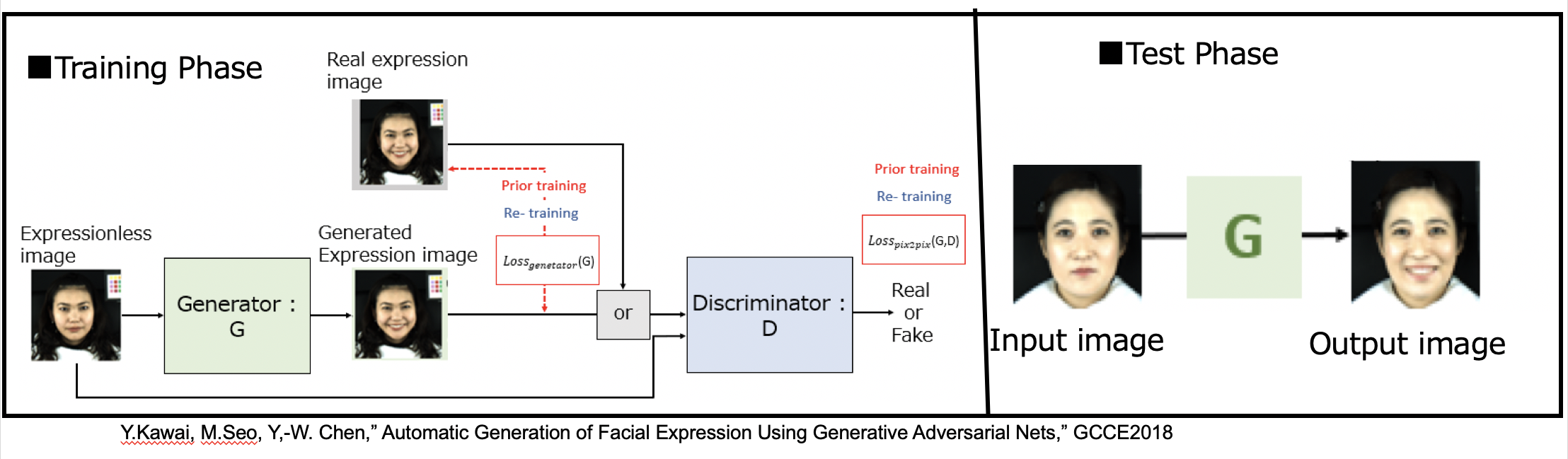
Fig.1. Overview of the proposed tatic-to-dynamic model (static2dynamic) based on a 3D conditional generative adversarial network
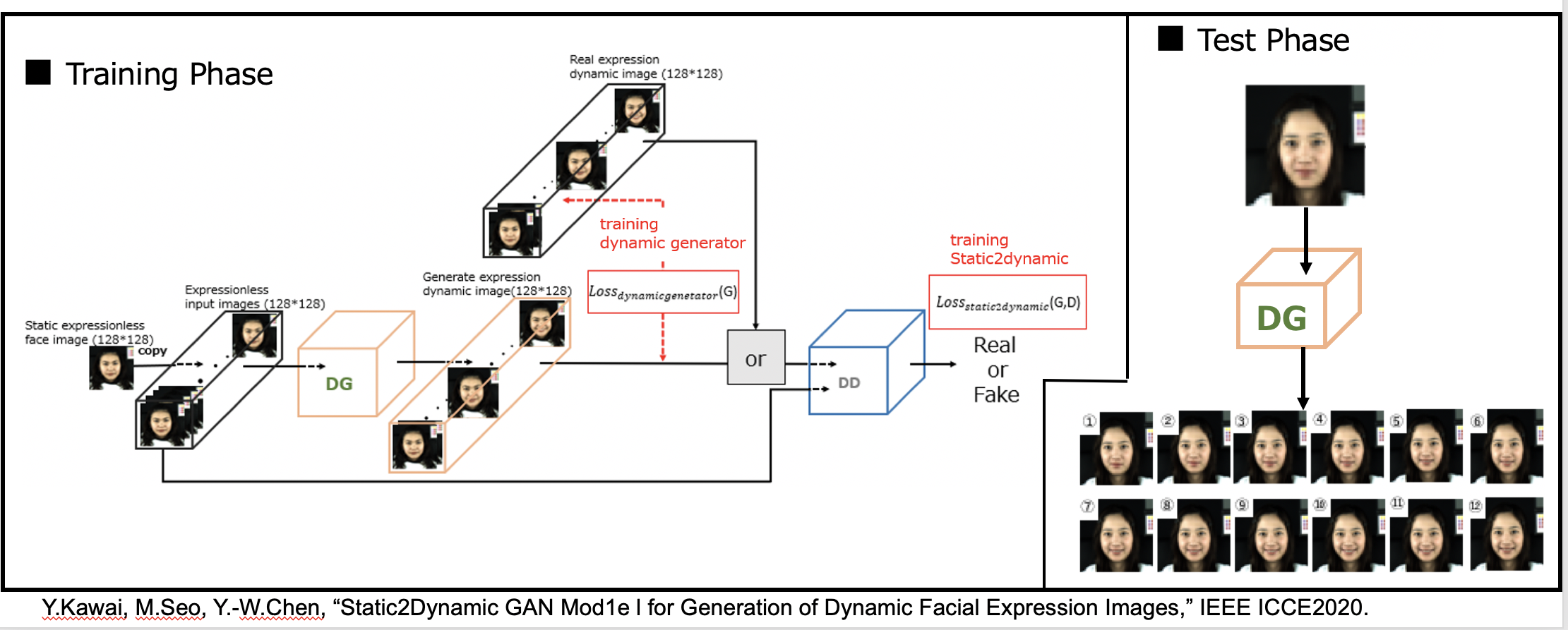
Fig.2. Typical generated expression images
Related Publications:
1. Yoshiharu Kawai, Masataka Seo, and *Yen-Wei Chen, “Static2Dynamic GAN Model for Generation of Dynamic Facial Expression Images,” 38th IEEE International Conference on Consumer Electronics (IEEE ICCE2020), Las Vegas, USA, Jan. 4-6, 2020.
2. Yoshiharu Kawai, Masataka Seo, Yen-Wei Chen, “Automatic Generation of Facial Expression Using Generative Adversarial Nets,” Proc. of 2018 IEEE 7th Global Conference on Consumer Electronics (GCCE 2018), Nara, Japan, Oct.9-12, 2018(Link)