GANによる画像生成
GAN(Generative Adversarial Network, 敵対的生成ネットワーク)は、生成器(Generator)と判別器(Discriminator)から構成されている。Fig.1にはその概念図を示す。Generatorは与えられた入力から画像を生成する。Discriminatorは入力が本物の画像かGeneratorが作った偽物なのかを判断する。GeneratorはDiscriminatorが本物だ判別させるように、DiscriminatorはGeneratorが作った偽物を見抜けるように、敵対させながら学習を行う。
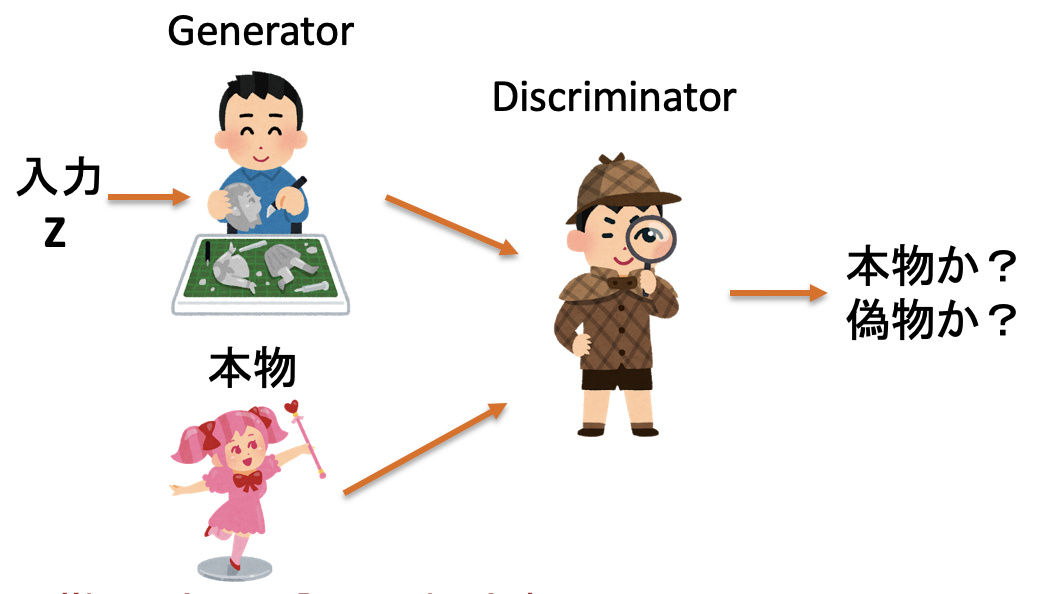
Fig.0-1. GANの概念図

Fig.0-2. AIによる画像生成例
GANは様々な画像生成に応用されているが、本研究室では、GANを利用した視線変換や、顔面神経麻痺患者のプライバシーを保護するための顔面神経麻痺患者の表情生成などの実用的な応用研究を行なっている。以下の三つの研究結果を紹介する。タイトルをクリックすると、詳細な説明がある。
研究事例1: Static2Dynamic GANを用いた表情動画像の生成
図1 GANを用いた表情画像(笑顔)の生成例。(左)真顔(入力画像);(中)生成された笑顔;(右)本笑顔 図2 再帰型cGANを用いた視線補正例 図3 CGANを用いた顔面神経麻痺患者の表情生成

研究事例2: 再帰型cGANを用いた視線補正

研究事例3: CGANを用いた顔面神経麻痺患者の表情生成
